AI Driven Course Curriculum Map Generation and Searching System
A fully accredited, nonprofit medical school training physicians
Client
A fully accredited, nonprofit medical school training physicians for practice in the United States and Canada. The institution positions itself as an exceptional alternative for qualified students who face limited medical school seats in North America. The client intended to utilize Generative AI technologies on Amazon Web Services (AWS) to implement an AI-driven system for ingesting IMSCC (IMS Common Cartridge) files and automatically generate a course curriculum map aligned to the AAMC framework.
Challenge
The client faced a time-intensive and inconsistent manual process for mapping course content to the AAMC (Association of American Medical Colleges) competency framework. With 22 courses and IMSCC files containing heterogeneous content — HTML pages, PDFs, PowerPoint slides, QTI assessments, and images — manual mapping was both error-prone and unscalable. Some IMSCC files exceeded 1.3 GB in size with 200+ resources, requiring processing times far beyond what Lambda's 15-minute execution limit could accommodate. The platform also lacked a searchable, structured store for generated curriculum maps and had no mechanism for aligning content across courses to surface prerequisite dependencies.
Key Results
- Delivered a fully automated, end-to-end curriculum mapping pipeline processing 22+ courses from raw IMSCC files to structured, AAMC-aligned curriculum maps
- Achieved intelligent AAMC competency alignment across all four domains: Interpersonal, Intrapersonal, Thinking and Reasoning, and Science Competencies
- Solved large-file processing challenge — files up to 1.3 GB processed within Lambda's 15-minute timeout using dynamic batch sizing and Step Functions orchestration
- Implemented prerequisite-aware module sequencing via two-pass dependency analysis, ensuring correct course ordering in final curriculum maps
- Deployed hybrid semantic and keyword search API over all processed curriculum content, accessible via API Gateway
- Built automatic model fallback from Claude Sonnet 4.5 to Claude Sonnet 4 when daily Bedrock token quotas are reached, ensuring pipeline continuity
- Delivered full infrastructure-as-code using Terraform across 50+ AWS resources for repeatable, multi-environment deployment
Solution
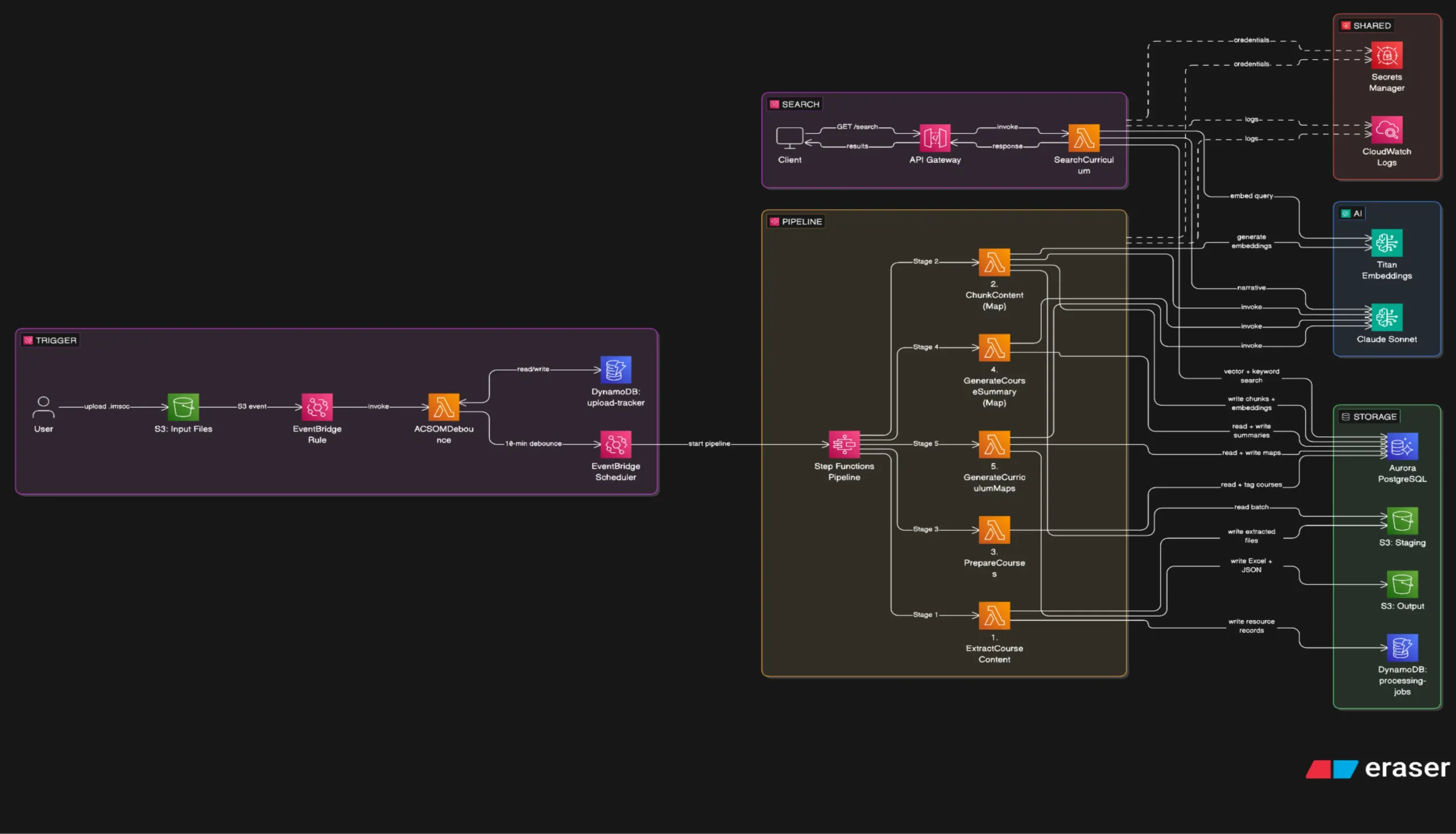
Event-Driven Batch Processing Pipeline
- We designed and implemented a fully serverless, event-driven batch processing pipeline on AWS.
- The system is not a chatbot or RAG architecture — it processes entire cohorts of courses once and generates comprehensive, structured curriculum maps that persist in Aurora PostgreSQL and S3 for downstream search and reporting.
- IMSCC files uploaded to S3 automatically trigger the pipeline after a configurable 10-minute debounce period, ensuring all files in a cohort are fully uploaded before processing begins.
Content Extraction and Hierarchical Chunking
- Unpacked and parsed IMSCC files, extracting imsmanifest.xml to build full resource graphs and course hierarchies
- Implemented file-type-specific extraction: HTML via BeautifulSoup, PDF via PyMuPDF, PPTX via python-pptx, DOCX via python-docx, QTI/XML for assessments, and Claude vision OCR for image-only pages
- Applied hierarchical chunking at 800 tokens with 100-token overlap using tiktoken, structured across three levels: Course → Module/Unit → Resource/Item
- Expanded large PDFs (over 25 pages) into 25-page parts to fit within batch time budgets; compressed images to max 1024px JPEG quality 70, reducing Bedrock token usage by 60-70%
- Generated Titan Embed Text v2 embeddings (1536 dimensions) for every chunk and stored them in Aurora PostgreSQL with pgvector
AAMC Competency Mapping and Course Summarization
- During chunking, Claude extracted learning objectives from each resource and mapped them to the four AAMC competency domains
- GenerateCourseSummary Lambda computed AAMC domain coverage percentages per course, with direct strategy (up to 120k tokens) and map_reduce strategy (batched summarization) for larger courses
- Structured JSON course summaries captured: title, description, key topics, prerequisite topics, AAMC domain coverage, and detailed module breakdowns
Two-Pass Curriculum Map Generation
- Pass 1 — Prerequisite Dependency Map: Claude analyzed each course's prerequisite topics against other courses' key topics to build an explicit dependency graph
- Pass 2 — Blueprint Generation: The dependency map was injected as ordering constraints; Claude generated a module sequence respecting all prerequisite relationships
- Pass 3 — Core and Supplementary Maps: Two full curriculum maps generated from the approved blueprint — one for required AAMC competencies, one for supplementary learning
- Outputs delivered as Excel workbooks (openpyxl) and JSON stored in S3, with structured records written to Aurora for search
Hybrid Semantic Search API
- Implemented hybrid search combining Titan v2 vector similarity (cosine) against chunk embeddings and PostgreSQL ILIKE keyword matching across chunk text and module titles
- Chunks appearing in both vector and keyword results ranked highest; Claude generates a natural language narrative summarizing top results with source attribution
- Exposed via API Gateway HTTP v2 GET /search endpoint with cohort-level filtering by input folder
Step Functions Orchestration for Scale
- AWS Step Functions orchestrated the complete pipeline with parallel Map states — up to 5 courses processed concurrently, with nested Map states for up to 3 batches per course
- Each Lambda invocation used ThreadPoolExecutor (3-5 workers) for concurrent Bedrock API calls, maximizing throughput within Lambda's timeout ceiling
- Built-in retry logic, checkpoint recovery, and idempotent reprocessing (force_reprocess flag) ensured resilience across long-running cohort runs
Technologies Used
- Amazon Bedrock — Claude Sonnet 4.5 (primary), Claude Sonnet 4 (fallback)
- Amazon Aurora PostgreSQL Serverless v2 with pgvector
- AWS Step Functions
- AWS Lambda (Python 3.12)
- Amazon S3
- Amazon DynamoDB
- Amazon EventBridge and EventBridge Scheduler
- API Gateway (HTTP v2)
- Amazon Titan Embed Text v2
- AWS Secrets Manager
Summary
A fully accredited nonprofit medical school enhanced its curriculum operations by implementing an AI-driven course curriculum map generation system on AWS. The solution automated the extraction and parsing of IMSCC course files, performed intelligent AAMC competency mapping using Amazon Bedrock Claude Sonnet, and generated prerequisite-aware curriculum maps for an entire cohort of 22+ courses. By combining AWS Step Functions orchestration, hierarchical chunking, and a hybrid semantic search API, the system addressed large-file processing challenges and delivered structured, searchable curriculum maps aligned to the four AAMC competency domains — significantly reducing manual effort and improving consistency across the institution's medical education program.
#arocom #artificialintelligence #machinelearning #datascience
